Iskanje določenega elementa v seznamu z »n« elementi je zelo počasno. Časovna zahtevnost je O(n). Zato se za iskanje elementov v urejenem seznamu uporablja preskočni seznam, ki nam omogoča iskanje v času O(\lg n). To je mogoče zato, ker pri iskanju, brisanju in vstavljanju določene elemente preskakujemo. Vsak element ima določeno višino. Iskanje začnemo pri stražarju, ki je visok toliko kolikor je visok najvišji element v seznamu. Če je vrednost naslednjega elementa, ki ima isto višino kot stražar, manjša ali enaka vrednosti iskanega elementa, skočimo na ta element. V nasprotnem primeru se spustimo za en nivo nižje in ponovimo vajo. Postopek ponavljamo dokler ne najdemo iskani element. Isti postopek uporabljamo pri brisanju in vstavljanju elementov. Da bo preskakovanje čim bolj učinkovito, morajo biti višine elementov naključne.
Javanski program, ki sem ga sprogramiral potrjujejo dejstvo, da vsak element v seznamu najdemo v \lg n korakov. Poleg tega nam naključnost zagotavlja, da so višine elementov enakomerno porazdeljene.
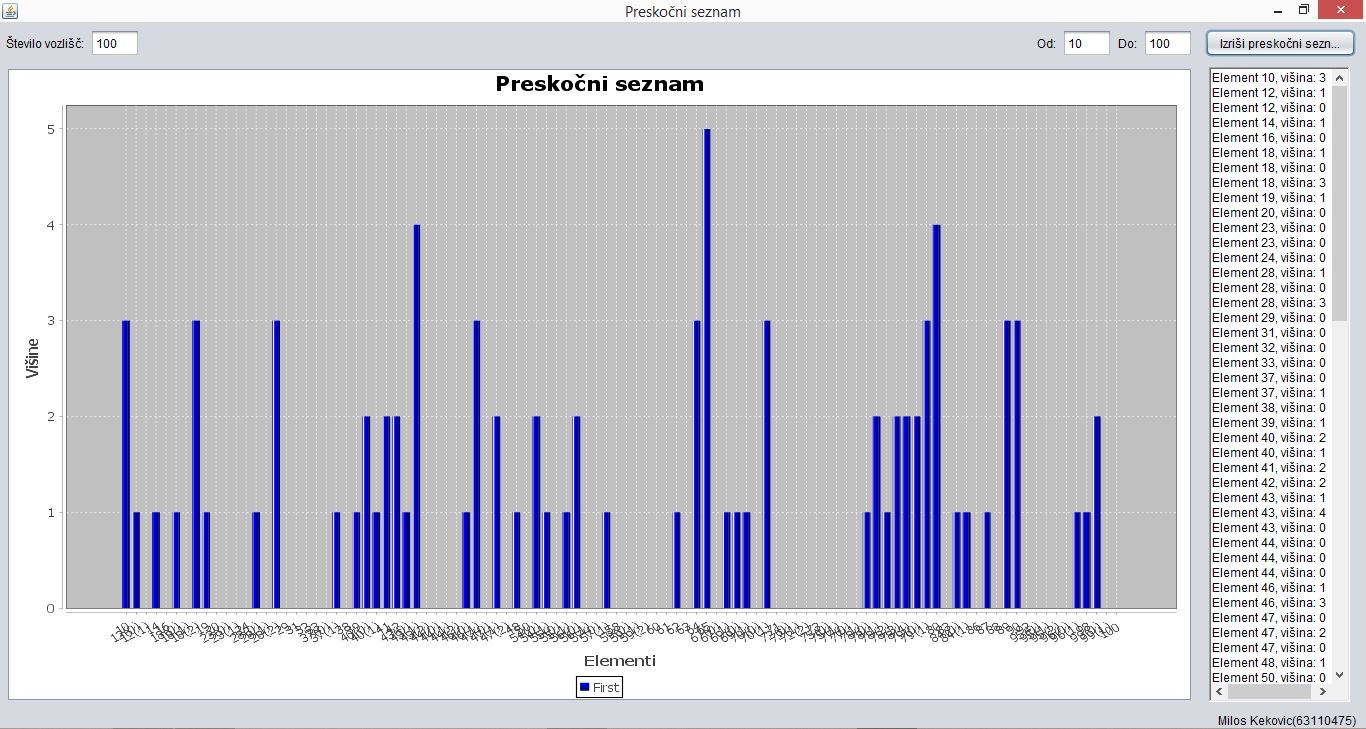
Primer:
Če imamo 100 elementov, mora veljati:
• višina najvišjega elementa l \leq \lceil \lg n \rceil. V tem primeru je l = 5, kar je manjše kot \lceil \lg n \rceil oz. 7. (pogostnost)
• višine morajo biti enako porazdeljene, kot so v tem primeru. (porazdeljenost)
• vsak nivo l ima pričakovano manj elementov kot jih je bilo na nivoju l-1. (pogostnost)